bloom filter java 布隆过滤器(Bloom Filter)原理及Guava中的具体实现

bloom filter java 布隆过滤器(Bloom Filter)原理及Guava中的具体实现
布隆过滤器(Bloom )原理及Guava中的具体实现
目录
引子
最近在研究推荐系统中已读内容排除以及重复内容去重相关的问题,布隆过滤器是解决这类问题最好的工具之一,很值得专门写一篇文章来详细讲解。
布隆过滤器介绍
布隆过滤器(Bloom ,下文简称BF)由 Bloom在1970年提出,是一种空间效率高的概率型数据结构。它专门用来检测集合中是否存在特定的元素。听起来是很稀松平常的需求,为什么要使用BF这种数据结构呢?
产生的契机
回想一下,我们平常在检测集合中是否存在某元素时,都会采用比较的方法。考虑以下情况:
总而言之,当集合中元素的数量极多时,不仅查找会变得很慢,而且占用的空间也会大到无法想象。BF就是解决这个矛盾的利器。
设计思想
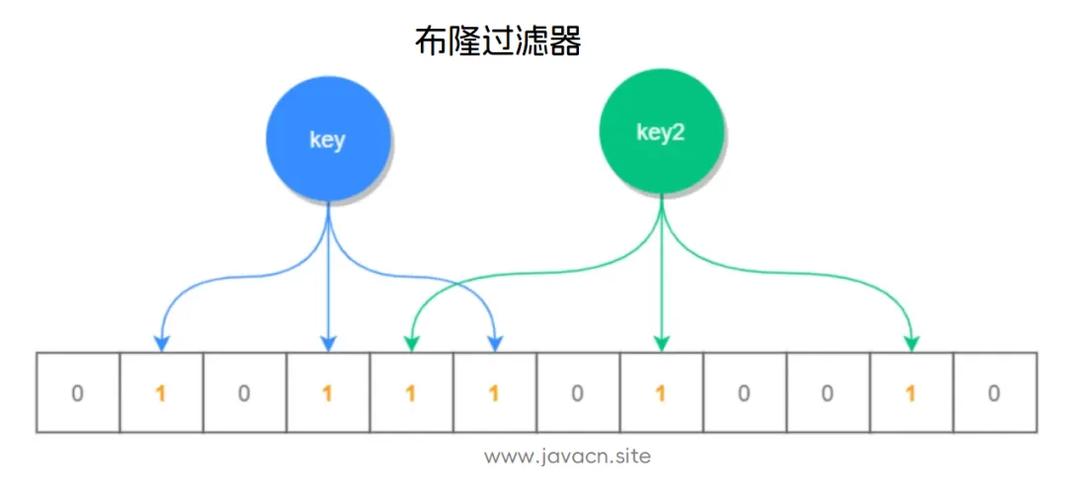
BF是由一个长度为m比特的位数组(bit array)与k个哈希函数(hash )组成的数据结构。位数组均初始化为0,所有哈希函数都可以分别把输入数据尽量均匀地散列。
当要插入一个元素时,将其数据分别输入k个哈希函数bloom filter java 布隆过滤器(Bloom Filter)原理及Guava中的具体实现,产生k个哈希值。以哈希值作为位数组中的下标,将所有k个对应的比特置为1。
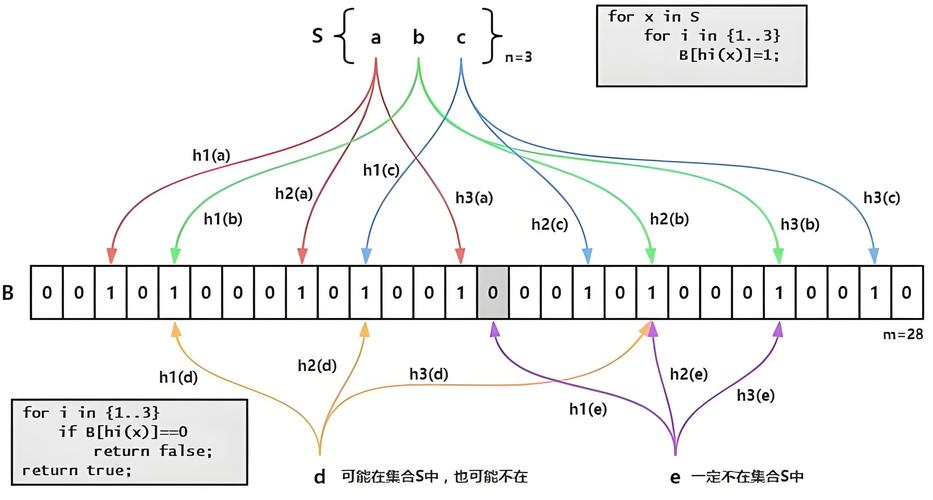
当要查询(即判断是否存在)一个元素时,同样将其数据输入哈希函数,然后检查对应的k个比特。如果有任意一个比特为0,表明该元素一定不在集合中。如果所有比特均为1,表明该集合有(较大的)可能性在集合中。为什么不是一定在集合中呢?因为一个比特被置为1有可能会受到其他元素的影响,这就是所谓“假阳性”(false )。相对地,“假阴性”(false )在BF中是绝不会出现的。
下图示出一个m=18, k=3的BF示例。集合中的x、y、z三个元素通过3个不同的哈希函数散列到位数组中。当查询元素w时,因为有一个比特为0,因此w不在该集合中。
优缺点与用途
BF的优点是显而易见的:
但是,它的缺点也同样明显:
所以,BF在对查准度要求没有那么苛刻,而对时间、空间效率要求较高的场合非常合适,本文第一句话提到的用途即属于此类。另外,由于它不存在假阴性问题,所以用作“不存在”逻辑的处理时有奇效,比如可以用来作为缓存系统(如Redis)的缓冲,防止缓存穿透。
假阳性率的计算
假阳性是BF最大的痛点,因此有必要权衡,比如计算一下假阳性的概率。为了简单一点,就假设我们的哈希函数选择位数组中的比特时,都是等概率的。当然在设计哈希函数时,也应该尽量满足均匀分布。
在位数组长度m的BF中插入一个元素,它的其中一个哈希函数会将某个特定的比特置为1。因此,在插入元素后,该比特仍然为0的概率是:
现有k个哈希函数,并插入n个元素,自然就可以得到该比特仍然为0的概率是:
反过来讲,它已经被置为1的概率就是:
也就是说,如果在插入n个元素后,我们用一个不在集合中的元素来检测,那么被误报为存在于集合中的概率(也就是所有哈希函数对应的比特都为1的概率)为:
当n比较大时,根据重要极限公式bloom filter java 布隆过滤器(Bloom Filter)原理及Guava中的具体实现,可以近似得出假阳性率:
所以,在哈希函数的个数k一定的情况下:
事实上,即使哈希函数不是等概率选择比特的,最终也会得出相同的结果,可以借助吾妻-霍夫丁不等式(Azuma- )证明。我数学比较垃圾,就不班门弄斧了。
有一些框架内已经内建了BF的实现,免去了自己实现的烦恼。下面以Guava为例,看看是怎么做的。
Guava中的布隆过滤器
采用Guava 27.0.1版本的源码,BF的具体逻辑位于mon.hash.类中。开始读代码吧。
类的成员属性
不多,只有4个。
/** The bit set of the BloomFilter (not necessarily power of 2!) */
private final LockFreeBitArray bits;
/** Number of hashes per element */
private final int numHashFunctions;
/** The funnel to translate Ts to bytes */
private final Funnel funnel;
/** The strategy we employ to map an element T to {@code numHashFunctions} bit indexes. */
private final Strategy strategy;
的构造
这个类的构造方法是私有的。要创建它的实例bloom filter javabloom filter java,应该通过公有的()方法。它一共有5种重载方法,但最终都是调用了如下的逻辑。
@VisibleForTesting
static BloomFilter create(
Funnel funnel, long expectedInsertions, double fpp, Strategy strategy) {
checkNotNull(funnel);
checkArgument(
expectedInsertions >= 0, "Expected insertions (%s) must be >= 0", expectedInsertions);
checkArgument(fpp > 0.0, "False positive probability (%s) must be > 0.0", fpp);
checkArgument(fpp < 1.0, "False positive probability (%s) must be < 1.0", fpp);
checkNotNull(strategy);
if (expectedInsertions == 0) {
expectedInsertions = 1;
}
/*
* TODO(user): Put a warning in the javadoc about tiny fpp values, since the resulting size
* is proportional to -log(p), but there is not much of a point after all, e.g.
* optimalM(1000, 0.0000000000000001) = 76680 which is less than 10kb. Who cares!
*/
long numBits = optimalNumOfBits(expectedInsertions, fpp);
int numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, numBits);
try {
return new BloomFilter(new LockFreeBitArray(numBits), numHashFunctions, funnel, strategy);
} catch (IllegalArgumentException e) {
throw new IllegalArgumentException("Could not create BloomFilter of " + numBits + " bits", e);
}
}
该方法接受4个参数:是插入数据的,是期望插入的元素总个数n,fpp即期望假阳性率p,即哈希策略。
由上可知,位数组的长度m和哈希函数的个数k分别通过()方法和tions()方法来估计。
估计最优m值和k值
@VisibleForTesting
static long optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (long) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
@VisibleForTesting
static int optimalNumOfHashFunctions(long n, long m) {
// (m / n) * log(2), but avoid truncation due to division!
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}
要看懂这两个方法,我们得接着上一节的推导继续做下去。
由假阳性率的近似计算方法可知,如果要使假阳性率尽量小,在m和n给定的情况下,k值应为:
这就是tions()方法的逻辑。那么m该如何估计呢?
将k代入上一节的式子并化简,我们可以整理出期望假阳性率p与m、n的关系:
亦即:
这就是()方法的逻辑。
从上也可以得出:
所以,在创建时,确定合适的p和n值很重要。
哈希策略
在s枚举中定义了两种哈希策略,都基于著名的算法,分别是和。前者是一个简化版,所以我们来看看后者的实现方法。
MURMUR128_MITZ_64() {
@Override
public boolean put(
T object, Funnel funnel, int numHashFunctions, LockFreeBitArray bits) {
long bitSize = bits.bitSize();
byte[] bytes = Hashing.murmur3_128().hashObject(object, funnel).getBytesInternal();
long hash1 = lowerEight(bytes);
long hash2 = upperEight(bytes);
boolean bitsChanged = false;
long combinedHash = hash1;
for (int i = 0; i < numHashFunctions; i++) {
// Make the combined hash positive and indexable
bitsChanged |= bits.set((combinedHash & Long.MAX_VALUE) % bitSize);
combinedHash += hash2;
}
return bitsChanged;
}
@Override
public boolean mightContain(
T object, Funnel funnel, int numHashFunctions, LockFreeBitArray bits) {
long bitSize = bits.bitSize();
byte[] bytes = Hashing.murmur3_128().hashObject(object, funnel).getBytesInternal();
long hash1 = lowerEight(bytes);
long hash2 = upperEight(bytes);
long combinedHash = hash1;
for (int i = 0; i < numHashFunctions; i++) {
// Make the combined hash positive and indexable
if (!bits.get((combinedHash & Long.MAX_VALUE) % bitSize)) {
return false;
}
combinedHash += hash2;
}
return true;
}
private /* static */ long lowerEight(byte[] bytes) {
return Longs.fromBytes(
bytes[7], bytes[6], bytes[5], bytes[4], bytes[3], bytes[2], bytes[1], bytes[0]);
}
private /* static */ long upperEight(byte[] bytes) {
return Longs.fromBytes(
bytes[15], bytes[14], bytes[13], bytes[12], bytes[11], bytes[10], bytes[9], bytes[8]);
}
};
其中put()方法负责向布隆过滤器中插入元素,()方法负责判断元素是否存在。以put()方法为例讲解一下流程吧。
使用算法对的输入数据进行散列,得到(16B)的字节数组。取低8字节作为第一个哈希值hash1,取高8字节作为第二个哈希值hash2。进行k次循环,每次循环都用hash1与hash2的复合哈希做散列,然后对m取模,将位数组中的对应比特设为1。
这里需要注意两点:
位数组具体实现
来看类的部分代码。
static final class LockFreeBitArray {
private static final int LONG_ADDRESSABLE_BITS = 6;
final AtomicLongArray data;
private final LongAddable bitCount;
LockFreeBitArray(long bits) {
this(new long[Ints.checkedCast(LongMath.divide(bits, 64, RoundingMode.CEILING))]);
}
// Used by serialization
LockFreeBitArray(long[] data) {
checkArgument(data.length > 0, "data length is zero!");
this.data = new AtomicLongArray(data);
this.bitCount = LongAddables.create();
long bitCount = 0;
for (long value : data) {
bitCount += Long.bitCount(value);
}
this.bitCount.add(bitCount);
}
/** Returns true if the bit changed value. */
boolean set(long bitIndex) {
if (get(bitIndex)) {
return false;
}
int longIndex = (int) (bitIndex >>> LONG_ADDRESSABLE_BITS);
long mask = 1L <>> 6)) & (1L << bitIndex)) != 0;
}
// ....
}
看官应该能明白为什么它要叫做“”了,因为它是采用原子类型作为位数组的存储的,确实不需要加锁。另外还有一个Guava中特有的类型的计数器,用来统计置为1的比特数。
采用除了有并发上的优势之外,更主要的是它可以表示非常长的位数组。一个长整型数占用64bit,因此data可以代表第0~63bit,data代表64~,data代表128~……依次类推。这样设计的话,将下标i无符号右移6位就可以获得data数组中对应的位置,再在其基础上左移i位就可以取得对应的比特了。
最后多嘴一句,上面的代码中用到了Long.()方法计算long型二进制表示中1的数量,堪称Java语言中最强的骚操作之一:
public static int bitCount(long i) {
// HD, Figure 5-14
i = i - ((i >>> 1) & 0x5555555555555555L);
i = (i & 0x3333333333333333L) + ((i >>> 2) & 0x3333333333333333L);
i = (i + (i >>> 4)) & 0x0f0f0f0f0f0f0f0fL;
i = i + (i >>> 8);
i = i + (i >>> 16);
i = i + (i >>> 32);
return (int)i & 0x7f;
}
总结
本文讲解了布隆过滤器的产生、设计思路和应用场景bloom filter java,通过简单推导明确了其假阳性问题。另外,又通过阅读Guava中的相关源码,了解了设计布隆过滤器的技术要点。之后还会另外写文章讲述我们在生产环境中的具体应用。
最后编辑于 :2020.02.06 15:51:28
©著作权归作者所有,转载或内容合作请联系作者
1. 本站所有资源来源于用户上传和网络,如有侵权请联系站长!
2. 分享目的仅供大家学习和交流,您必须在下载后24小时内删除!
3. 不得使用于非法商业用途,不得违反国家法律。否则后果自负!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系站长处理!
6. 本站不售卖代码,资源标价只是站长收集整理的辛苦费!如果您喜欢该程序,请支持正版软件,购买注册,得到更好的正版服务。
7. 站长QQ号码 2205675299
资源库 - 资源分享下载网 » bloom filter java 布隆过滤器(Bloom Filter)原理及Guava中的具体实现

常见问题FAQ
- 关于资源售价和售后服务的说明?
- 代码有没有售后服务和技术支持?
- 有没有搭建服务?
- 链接地址失效了怎么办?
- 关于解压密码