cassandra hbase 一文了解 Hbase 列式数据库

cassandra hbase 一文了解 Hbase 列式数据库
【作者】赵海
1. 什么是 Hbase ?
HBase 是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,目标是存储并处理大型的数据。
HBase 是 的开源实现,不同之处在于: 使用 GFS 作为其文件存储系统, HBase 利用 HDFS 作为其文件存储系统; 利用 作为协同服务, HBASE 利用 作为协同服务。
Hbase 是一个面向列存储的分布式存储系统,它的优点在于可以实现高性能的并发读写操作,同时 Hbase 还会对数据进行透明的切分,这样就使得存储本身具有了水平伸缩性。
2. Hbase 的数据模型是什么样的?
HBase 的数据存储模型当中包含以下几个概念:
1 、 row :一行数据包含一个唯一标识 Row-Key 、多个 以及对应的值。在 HBase 中,一张表中所有 row 都按照 Row-Key 的字典序(二进制位移计算)由小到大排序。
2 、 :与关系型数据库中的列不同,HBase 中的 由 (列簇)以及 (列名)两部分组成。 在表创建的时候需要指定cassandra hbase 一文了解 Hbase 列式数据库,用户不能随意增减。 下可以设置任意多个cassandra hbase,因此可以理解为 HBase 中的列可以动态增加。
3 、 cell :单元格,由五元组( row , , , type , value )组成的结构,其中 type 表示 Put/ 这样的操作类型, 代表这个 cell 的版本。这个结构在数据库中实际是以 KV 结构存储的,其中( row , , , type )是 K , value 字段对应 KV 结构的 V 。
4 、 :每个 cell 在写入 HBase 的时候都会默认分配一个时间戳作为该 cell 的版本, HBase 支持多版本特性,即同一 Row-Key 、 下可以有多个 value 存在,这些 value 使用 作为版本号。
HBase 是一个面向列的数据库,在表中它由行排序。表模式定义只能列族,也就是键值对。一个表有多个列族以及 每一个列族可以有任意数量的列 。后续列的值连续存储在磁盘上。表中的每个单元格值都具有时间戳。总之,在一个 HBase :表是行的集合,行是列族的集合,列族是列的集合,列是键值对的集合。
表 1 逻辑存储视图

表 2 物理存储视图
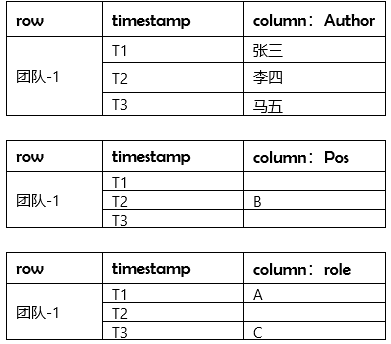
HBase 的逻辑存储视图由行键、时间戳、列族组成一个类似二维表一样的结构,但是在实际存储的时候,数据库存储的数据是以列族为单位进行存储的,是完全将行数据按列族的方式进行分列。
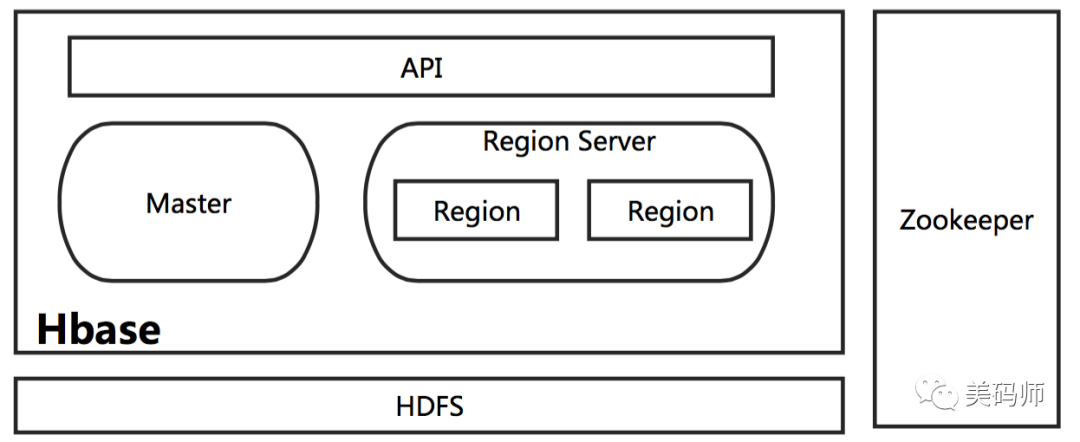
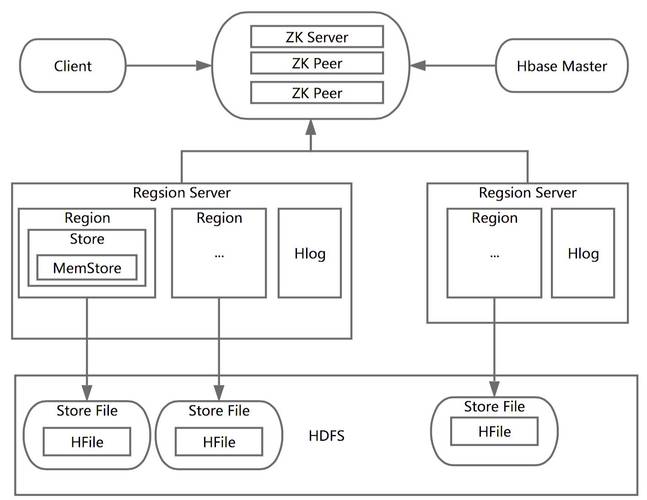
3. Hbase 的存储架构是什么样的?
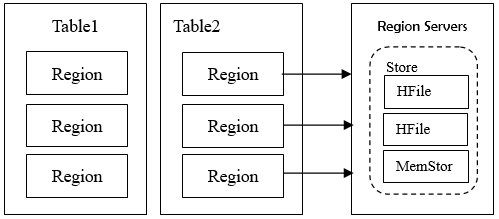
图 1 Hbase 物理存储架构
是 HBase 中分布式存储和负载均衡的最小单元,不同的 分布到不同的 上cassandra hbase 一文了解 Hbase 列式数据库,如图 、 中均有多个 ,这些 分布在不同的 中。 虽然是分布式分布式存储的最小单元,但并不是存储的最小单元, Store 是存储的最小单元。 由一个或者多个 Store 组成,每个 Store 会保存一个 ;每个 Store 又由一个 或 0 至多个 Hfile 组成; 存储在内存中, HFile 存储在 HDFS 中。
Hbase 在数据存储的过程当中,涉及到的物理对象分为如下:
1 、 : 负责 DDL 创建或删除 ,同一时间只能有一个 状态的 存在。
2 、 : 判定 的状态,记录 Meta Table 的具体位置;
3 、 : 一张 的一个分片( Shard ),记录着 key 的开始和结束;
4 、 WAL: 预写日志,持久化且顺序存储,一个 维护一套 WAL ;
5 、 : 中维护多个 , 里包含 以及多个 ;
6 、 : 对应一个 的 ,存在于文件缓存中cassandra hbase,拥有文件句柄;
7 、 : 读缓存,存于内存;(Row-Key – > row) ;
8 、 : 从 Flush 出来的文件,本身是持久化的,存储于 HDFS 的 之中,每次 Flush 生成一个新的 HFile 文件,文件包含有序的键值对序列。
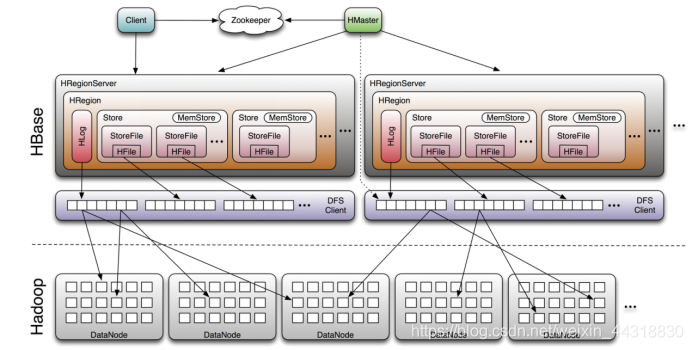
4. Hbase 是如何进行数据的读写?
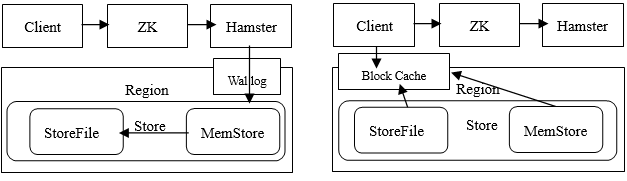
图 2 Hbase 读写原理图
数据写入流程(如左图):
1 、客户端首先从 找到 meta 表的 位置,然后读取 meta 表中的数据, meta 表中存储了用户表的 信息。
2 、根据 、表名和 Row-Key 信息。找到写入数据对应的 信息
3 、找到这个 对应的 ,然后发送请求。
4 、把数据分别写到 HLog ( write ahead log )和 各一份。
5 、 达到阈值后把数据刷到磁盘,生成 文件。
6 、删除 HLog 中的历史数据。
数据读出流程(如右图):
1 、客户端首先与 进行连接;从 找到 meta 表的 位置,即 meta 表的数据存储在某一 上;客户端与此 建立连接,然后读取 meta 表中的数据;meta 表中存储了所有用户表的 信息,我们可以通过 scan ‘hbase:meta’ 来查看 meta 表信息。
2 、根据要查询的 、表名和 Row-Key 信息。找到写入数据对应的 信息。
3 、找到这个 对应的 发送请求,并找到相应 。
4 、先从 查找数据,如果没有,再从 上读取。
5 、如果 中也没有找到,再到 上进行读取,从 中读取到数据之后,不是直接把结果数据返回给客户端,而是把数据先写入到 中,目的是为了加快后续的查询;然后在返回结果给客户端。
5. Hbase 的存储引擎是什么类型的?
首先需要确定的是 Hbase 的存储引擎是 LSM-Tree (可以参考之前的文章:)。
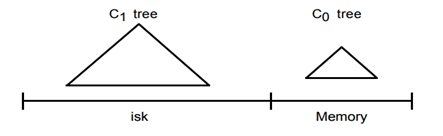
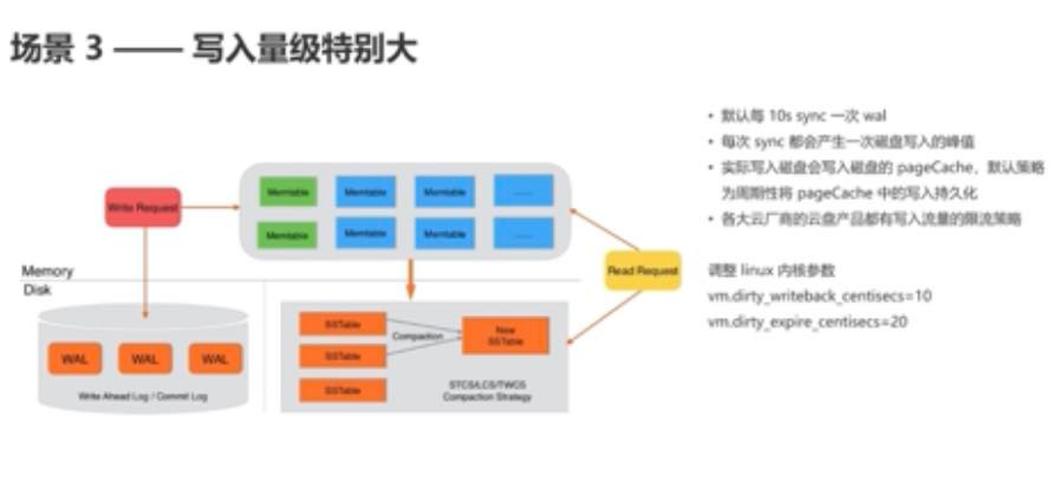
通过之前文章对 LSM-Tree 的介绍,我们知道 LSM-Tree 相比较 B+Tree 而言,最大的特点就是在于通过牺牲部分读性能,利用分层合并的思想,将小树合并为大树,将无序数据合并为有序数据,然后统一刷入磁盘,从而大大提高了写的性能。那么 HBase 套用到 LSM 中, 就是 LSM 当中的 ,也就是 C0 层的小树写入, 就是 LSM 当中的 ,也就是 Cn 层的合并之后的树的顺序写入。
除此之外 Hbase 在实现 Hbase 的时候,其实还是有自己独到的地方:
1 、 Minor vs Major :Minor ,根据配置策略,自动检查小文件,合并到大文件,从而减少碎片文件,然而并不会立马删除掉旧 HFile 文件;Major ,每个 CF 中,不管有多少个 文件,最终都是将 合并到一个大的 HFile 中,并且把所有的旧 HFile 文件删除,即 CF 与 HFile 最终变成一一对应的关系。
2 、 :除了 (也就是 ) 以外, HBase 还提供了另一种缓存结构, 。 本质上是将热数据放到内存里维护起来,避免 Disk I/O ,当然即使 找不到数据还是可以去 中找的,只有两边都不存在数据的时候,才会读内存里的 HFile 索引寻址到硬盘,进行一次 I/O 操作。HBase 将 和 搭配使用,称之为 。系统在 中主要存储 Index Block ,而将 Data Block 存储在 中。因此一次随机读需要首先在 中查到对应的 Index Block ,然后再到 查找对应数据块。
3 、 HFile :HFile 的数据结构也是 Hbase 的重要改进之处。
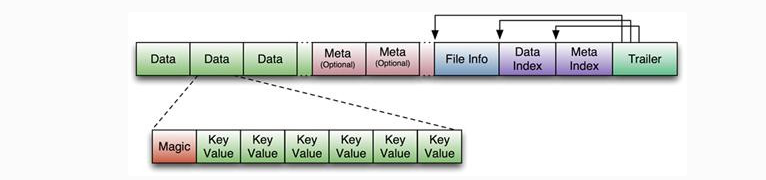
图示是 HFile 的数据结构,主要包含四个部分:数据块、头信息、索引信息、地址信息。索引就是 HFile 内置的一个 B+ 树索引,当 启动后并且 HFile 被打开的时候,这个索引会被加载到 Block Cache 即内存里; 存储在增长中的队列中的数据块里,数据块可以指定大小,默认 64k ,数据块越大,顺序检索能力越强;数据块越小,随机读写能力越强,需要权衡。
6. Hbase 与传统的 RDBMS 有什么区别?
表 4 列式数据库与关系型数据库的区别
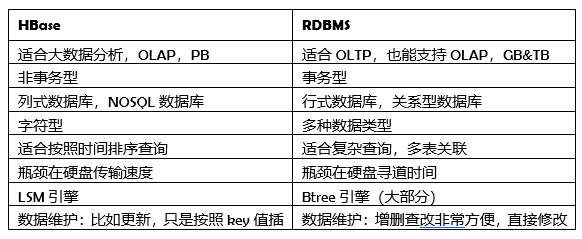
介绍了很多 HBase 与 RDBMS 的区别。那么什么时候最需要 HBase ,或者说 HBase 是否可以替代原有的 RDBMS ?对于这个问题,我们必须时刻谨记 HBase 并不适合所有场景,其最终目标并不是完全替代 RDBMS ,而是对 RDBMS 的一个重要补充。当需要考量 HBase 作为一个备选选型产品的时候,我们需要考虑以下几个关键问题。
1、 业务场景是否符合非 ACID 事务原则?
2、 数据的业务特性上是否需要复杂查询cassandra hbase,例如 SQL 实现的复杂连接、排序、复杂条件等?
3、 业务场景是不是可以通过读取列族数据的方式更有效地实现,数据是否可以用字符型表示?
4、 数据量是否足够发挥 Hbase 列式数据库的优势?
5、 是否可以找到合适的 Row-key ?随机性的 Row-key 适合频繁写,有序的 Row-key 适合大量的读。
7. Hbase 如何解决热点的问题?
HBase 中的行是按照 Row-Key 的字典顺序排序的,这种设计优化了扫描操作,可以将相关的行存放在临近位置,便于扫描。然而糟糕的 Row-Key 设计是热点的源头。一旦由于 Row-Key 设计与业务场景不相符,大量访问会使热点 所在的单个机器超出自身承受能力,引起性能下降甚至不可用,这也会影响同一个 上的其他 。
那么如何避免这样的问题发生呢?通常会有以下几种设计思想可供参考:
1 、反转:将 Row-Key 的字符串可变的部分提到前面,相对固定的部分提到后面。这样就会打乱 Row-Key 的有序性,在一定程度上降低了批量数据写的性能,但是读的时候就会减少热点查询,通过牺牲部分写的性能而提升读的性能。
2 、前缀:将每一个 Row-Key 加一个随机字符前缀,使得数据分散在多个不同的 ,达到 负载均衡的目标。最终消除局部热点,解决热点读写的问题。
3 、散列:通过哈希散列的方式将 Row-Key 重新设计,使得数据分散在不同的 ,同时效果要比前缀的方式更好,因为在读的时候,它是可以通过哈希的计算减少读性能的损耗。既解决了热点问题,同时也不必消耗太多的读性能。
原题:NOSQL DB:Hbase 列式数据库七问
1. 本站所有资源来源于用户上传和网络,如有侵权请联系站长!
2. 分享目的仅供大家学习和交流,您必须在下载后24小时内删除!
3. 不得使用于非法商业用途,不得违反国家法律。否则后果自负!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系站长处理!
6. 本站不售卖代码,资源标价只是站长收集整理的辛苦费!如果您喜欢该程序,请支持正版软件,购买注册,得到更好的正版服务。
7. 站长QQ号码 2205675299
资源库 - 资源分享下载网 » cassandra hbase 一文了解 Hbase 列式数据库

常见问题FAQ
- 关于资源售价和售后服务的说明?
- 代码有没有售后服务和技术支持?
- 有没有搭建服务?
- 链接地址失效了怎么办?
- 关于解压密码