cassandra hbase HBase底层原理(多维度分析)

cassandra hbase HBase底层原理(多维度分析)
本篇博客,小菌为大家带来的是关于HBase底层原理的讲解!
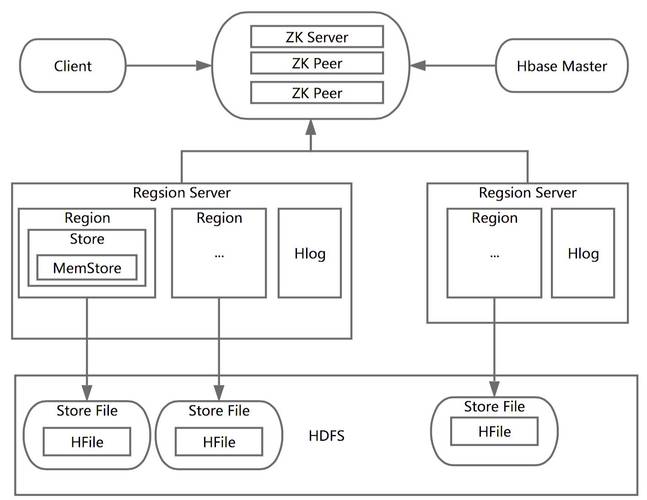
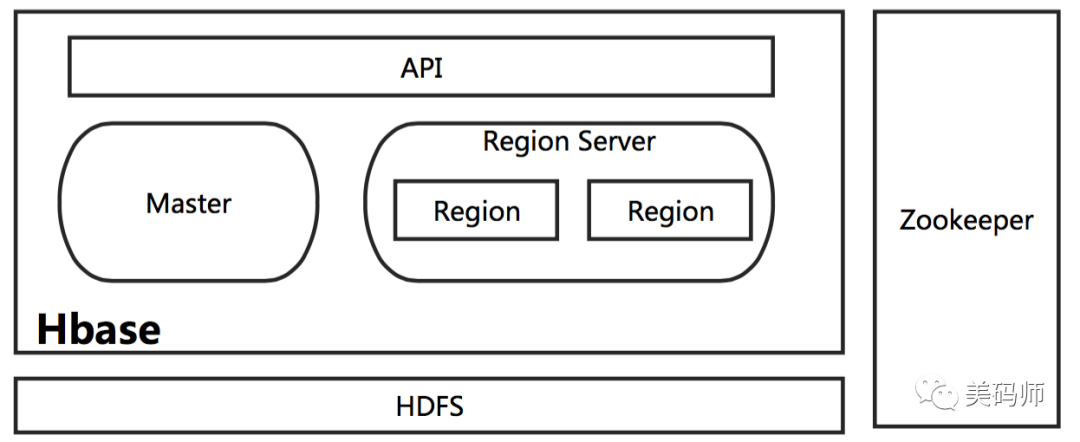
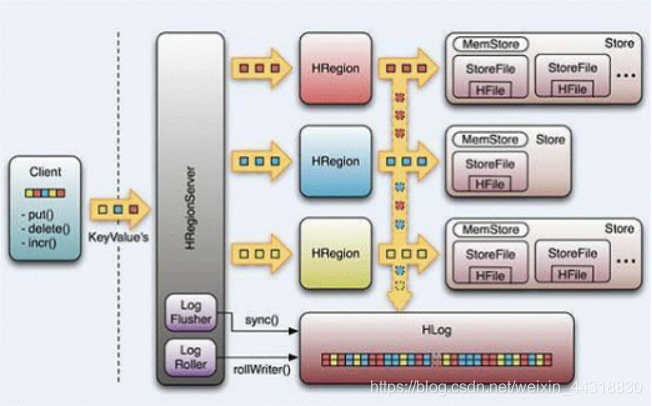
先上HBase的系统架构图
系统架构
是不是看的N脸懵圈

不用担心,相信看了我下面的细化分析,肯定能让你恍然大悟~
HBase主要分为以下几个部分组成:
:
也就是我们所谓的”客户端”,作为访问数据的入口,包含访问hbase的API接口,维护着一些cache(高速缓存存储器)来加快hbase的访问。
:
1.的选举机制保证任何时候,集群中只有一个
2.实时监控 的状态,将 的上线和下线信息实时通知给
3.存储Hbase的(元数据),包括有哪些table,每个table有哪些 (列族)
4.存贮所有的寻址入口
1.为 分配
2.负责 的负载均衡
3.发现失效的 并重新分配其上的
4.处理(元数据)更新请求
说明: 短时间下线,hbase集群依然可用,长时间不行。
1. 维护分配给它的,处理对这些的IO请求
2. 负责切分在运行过程中变得过大的
可以看到,访问 hbase 上数据的过程并不需要参与(寻址访问 和cassandra hbase,数据读写访问 ), 仅仅维护者table和的元数据信息,负载很低。
HBase的表数据模型

Row Key
与nosql数据库们一样,row key是用来检索记录的主键。访问hbase table中的行,只有三种方式:
1.通过单个row key访问
2.通过row key的range
3.全表扫描
Row key行键 (Row key)可以是任意字符串(最大长度是 64KB,实际应用中长度一般为 10-),在hbase内部,row key保存为字节数组。Hbase会对表中的数据按照排序(字典顺序)
存储时,数据按照Row key的字典序(byte order)排序存储。设计key时,要充分考虑排序存储这个特性,将经常一起读取的行存储放到一起。(位置相关性)
注意:字典序对int排序的结果是1,10,100,11,12,13,14,15,16,17,18,19,2,20,21,…,9,91,92,93,94,95,96,97,98,99。要保持整形的自然序,行键必须用0作左填充。行的一次读写是原子操作 (不论一次读写多少列)。这个设计决策能够使用户很容易的理解程序在对同一个行进行并发更新操作时的行为。
列族
hbase表中的每个列,都归属与某个列族。列族是表的的一部分(而列不是),必须在使用表之前定义。(包含表名和列族)
列名都以列族作为前缀。例如: ,:math 都属于 这个列族。
访问控制、磁盘和内存的使用统计都是在列族层面进行的。 列族越多cassandra hbase HBase底层原理(多维度分析),在取一行数据时所要参与IO、搜寻的文件就越多,所以,如果没有必要cassandra hbase,不要设置太多的列族
列
列族下面的具体列,属于某一个,类似于我们mysql当初创建的具体的列。
时间戳
HBase中通过row和确定的为一个存贮单元称为cell。每个 cell都保存着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是 64位整型。时间戳可以由hbase(在数据写入时自动 )赋值,此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显式赋值。如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。每个 cell中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
为了避免数据存在过多版本造成的的管理 (包括存贮和索引)负担,hbase提供了两种数据版本回收方式:
用户可以针对每个列族进行设置。
Cell
Cell是存储数据的最小单位。由{row key, ( = + ), } 唯一确定的单元。
Cell中的数据是没有类型的,全部是字节码形式存贮。
数据的版本号,每条数据可以有多个版本号,默认值为系统时间戳,类型为Long
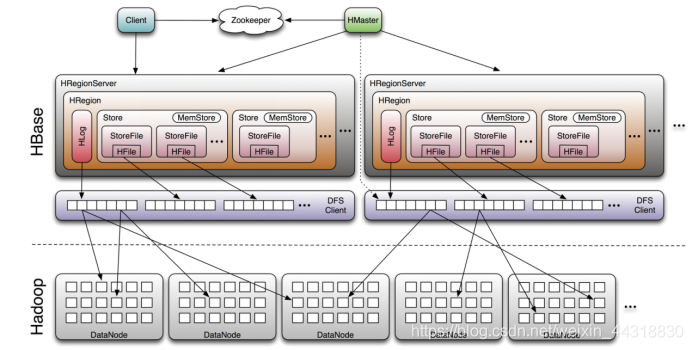
HBase的物理存储整体结构
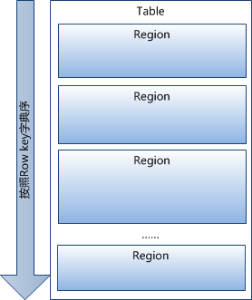
Table中的所有行都按照row key的字典序排列。Table 在行的方向上分割为多个。
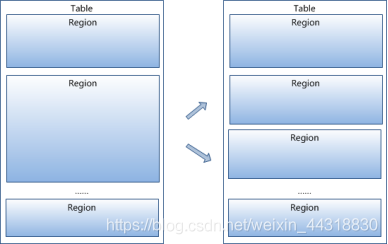
按大小分割的(默认10G),每个表一开始只有一个,随着数据不断插入表,不断增大,当增大到一个阈值的时候,就会等分会两个新的。当table中的行不断增多cassandra hbase,就会有越来越多的。
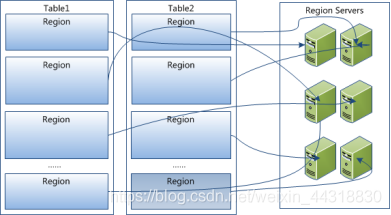
是Hbase中分布式存储和负载均衡的最小单元。最小单元就表示不同的可以分布在不同的 上。但一个是不会拆分到多个上的,也就是说一个只能属于一个。
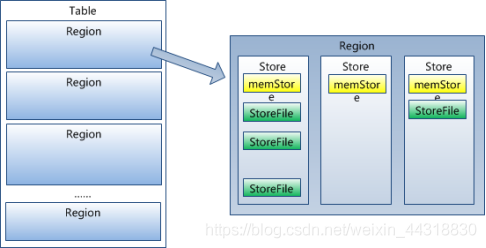
虽然是负载均衡的最小单元,但并不是物理存储的最小单元。 事实上,由一个或者多个Store组成,每个store保存一个 (列族)。 每个又由一个和0至多个组成。如上图
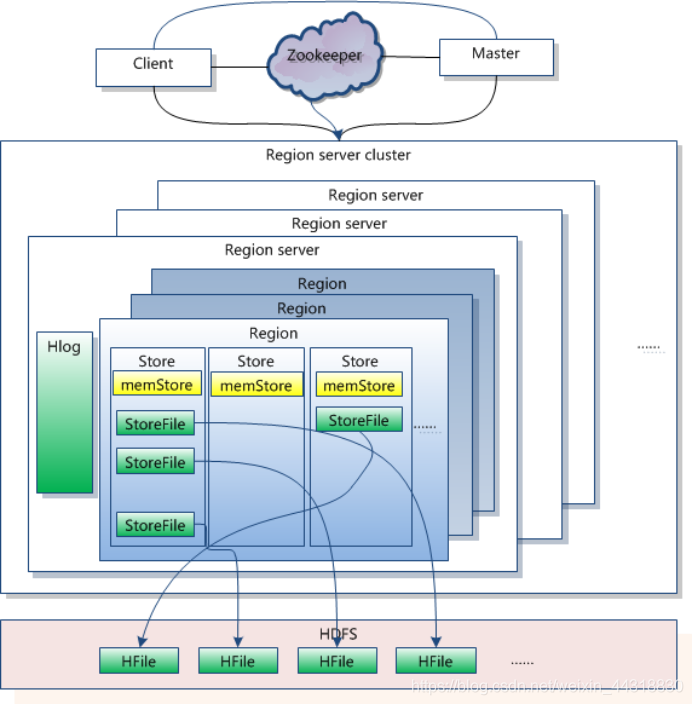
总体架构分布图:
STORE FILE & HFILE结构
以HFile格式保存在HDFS上。
HFile 的格式为:
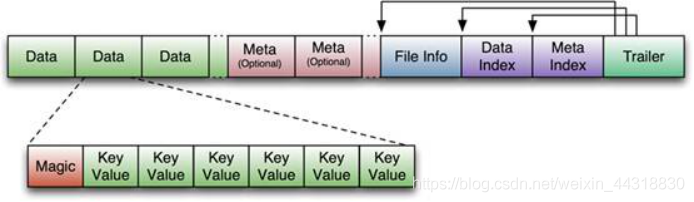
首先HFile文件是不定长的,长度固定的只有其中的两块:和。正如图中所示的,中有指针指向其他数据块的起始点。
File Info中记录了文件的一些Meta信息,例如:, , , , 等。
Data Index和Meta Index块记录了每个Data块和Meta块的起始点。
Data Block是HBase I/O的基本单元,为了提高效率,中有基于LRU的Block Cache机制。每个Data块的大小可以在创建一个Table的时候通过参数指定,大号的Block有利于顺序Scan,小号Block利于随机查询。 每个Data块除了开头的Magic以外就是一个个对拼接而成, Magic内容就是一些随机数字,目的是防止数据损坏。
HFile里面的每个对就是一个简单的byte数组。但是这个byte数组里面包含了很多项,并且有固定的结构。我们来看看里面的具体结构:

开始是两个固定长度的数值,分别表示Key的长度和Value的长度。紧接着是Key,开始是固定长度的数值,表示的长度,紧接着是 ,然后是固定长度的数值,表示的长度,然后是,接着是(限定符),然后是两个固定长度的数值,表示Time Stamp和Key Type(Put/)。Value部分没有这么复杂的结构,就是纯粹的二进制数据了。
File分为6个部分。
HFile的Data Block,Meta Block通常采用压缩方式存储,压缩之后可以大大减少网络IO和磁盘IO,随之而来的开销当然是需要花费cpu进行压缩和解压缩。目标Hfile的压缩支持两种方式:Gzip,Lzo。
与
一个由多个store组成,每个store包含一个列族的所有数据。Store包括位于内存的和位于硬盘的
写操作先写入,当中的数据量达到某个阈值,启动进程写入,每次写入形成单独一个,输出多个后,当数量达到阈值时,将多个合并成一个大的。当大小超过一定阈值后,会把当前的分割成两个,并由分配给相应的服务器,实现负载均衡。
客户端检索数据时,先在找,找不到再找
HLog(WAL log)
WAL 意为Write ahead log,类似mysql中的,用来做灾难恢复时用,Hlog记录数据的所有变更,一旦数据修改,就可以从log中进行恢复。
每个 维护一个Hlog,并且每个 中也仅有一个Hlog。这样不同(来自不同table)的日志会混在一起,这样做的目的是不断追加单个文件相对于同时写多个文件而言,可以减少磁盘寻址次数,因此可以提高对table的写性能。带来的麻烦是,如果一台 下线,为了恢复其上的,需要将 上的log进行拆分cassandra hbase HBase底层原理(多维度分析),然后分发到其它 上进行恢复。
Hlog的切分机制
1.当数据写入hlog以后,hbase发生异常,关闭当前的hlog文件
2.当日志的大小达到HDFS数据块的0.95倍的时候,关闭当前日志,生成新的日志
3.每隔一小时生成一个新的日志文件HLog文件就是一个普通的 File:
好了本次的分享到这里就结束了,受益的小伙伴或对大数据技术感兴趣的朋友记得关注小菌哟(^U^)ノ~YO
1. 本站所有资源来源于用户上传和网络,如有侵权请联系站长!
2. 分享目的仅供大家学习和交流,您必须在下载后24小时内删除!
3. 不得使用于非法商业用途,不得违反国家法律。否则后果自负!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系站长处理!
6. 本站不售卖代码,资源标价只是站长收集整理的辛苦费!如果您喜欢该程序,请支持正版软件,购买注册,得到更好的正版服务。
7. 站长QQ号码 2205675299
资源库 - 资源分享下载网 » cassandra hbase HBase底层原理(多维度分析)

常见问题FAQ
- 关于资源售价和售后服务的说明?
- 代码有没有售后服务和技术支持?
- 有没有搭建服务?
- 链接地址失效了怎么办?
- 关于解压密码