bloom filter java 【数据结构】布隆过滤器:BloomFilter原理及Java实现

bloom filter java 【数据结构】布隆过滤器:BloomFilter原理及Java实现
布隆过滤器(Bloom )是一个叫做 Bloom 的大佬在1970年提出的。我们可以把它看做由二进制向量(或者说数组)和一系列随机映射函数(哈希函数)两部分组成的数据结构。相比于我们平时用的 List,Set,Map 等容器,它占用的空间更少且效率更高,但缺点是其返回的结果是概率性的,而不是非常准确的。理论情况下添加到集合中的元素越多,误报的可能性就越大。并且,存放在布隆过滤器的数据不容易删除。
它的基本思想是:当一个元素被加入集合时,通过 K 个散列函数将这个元素映射成一个位数组中的 K 个点,把它们置为1;检索时,只要看看这些点是不是都是1 就(大约)知道集合中有没有它了——如果这些点有任何一个0,则被检元素一定不在,如果都是1,则被检元素很可能在。
1.原理
布隆过滤器(Bloom )核心实现是一个超大的位数组和几个哈希函数。如下图所示,有一个大小为 12 的数组,然后有3个哈希函数:
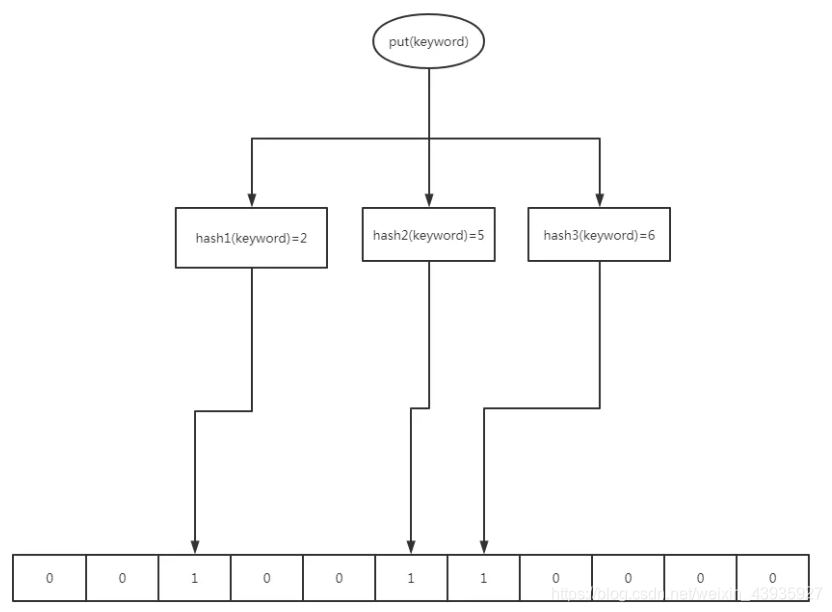
1.1 流程分析
假如现在有一个 要放入某个容器了bloom filter java,现在要经过Bloom ,具体的操作流程如下:
过滤器初始化:将位数组进行初始化,即数组每位都设置位0
放入元素:
对于集合里面的每一个元素,将元素依次通过3个哈希函数进行映射,每次映射都会产生一个哈希值每个计算得到的哈希值对应位数组上面的一个点bloom filter java,所以将位数组对应的位置标记为1
判断存在:查询W元素是否存在集合中的时候,同样的方法将W通过哈希映射到位数组上的3个点
因为此处不能判断该元素是否一定存在集合中,可能存在一定的误判率。
1.2 误差分析
可以从图中可以看到,向容器中 put 时,x1映射到(2/4/8),x2映射到(4/6/10):
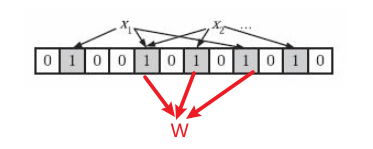
假设现在要判断元素 W 是否在容器中,通过哈希函数计算出的结果是(4/6/8),虽然指定位都为1,但显然没有这个元素。因此这种情况说明元素虽然不在集合中,也可能对应的都是1,这是误判率存在的原因。
2.应用场景
在很多场景下,我们都需要一个能迅速判断一个元素是否在一个集合中。譬如:
网页爬虫对URL的去重,避免爬取相同的URL地址反垃圾邮件,从数十亿个垃圾邮件列表中判断某邮箱是否垃圾邮箱(同理,垃圾短信)缓存击穿,将已存在的缓存放到布隆中,当黑客访问不存在的缓存时迅速返回避免缓存及DB挂掉
问题:
可能有人会问,我们直接把这些数据都放到数据库或者redis之类的缓存中不就行了,查询时直接匹配不就OK了?
是的,当这个集合量比较小,你内存又够大时,是可以这样做,你可以直接弄个、就OK了。但是当这个量以数十亿计,内存装不下,数据库检索极慢时该怎么办。
4种解决方案:
将所有垃圾邮箱地址存到数据库,匹配时遍历用存储所有地址,匹配时接近O(1)的效率查出来将地址用MD5算法或其他单向映射算法计算后存入,无论地址多大bloom filter java 【数据结构】布隆过滤器:BloomFilter原理及Java实现,保存的只有MD5后的固定位数布隆过滤器,将所有地址经过多个Hash算法,映射到一个bit数组
4种方案优劣:
方案1,因为是保存完整的地址,占用空间大。一个地址16字节,10亿即可达到上百G的内存。而且数据库的查询效率也比不上等数据结构方案2,虽然效率逼近O(1),但底层的扩容因子是0.75,也就是你想存75个数,至少需要一个100的数组,而且还会有不少的冲突。实际上bloom filter java,Hash的存储效率是0.5左右,存5个数需要10个的空间。算起来占用空间还是挺大的方案3,因为保存部分信息,所以占用空间小于存储完整信息,但仍然存在冲突的可能(非垃圾邮箱可能MD5后和某垃圾邮箱一样,概率低)方案4,将所有地址经过Hash后映射到同一个bit数组,因为只有一个超大的bit数组,保存所有的映射,占用空间极小,冲突概率高。只要概率在可以接受的范围,用时间换空间
可以看到,每种方案都有自己的不足之处,所以一定要根据数据规模和业务需求来确定到底使用什么。
3. 代码实现
下面就直接贴代码,注释已经写得很详细了,而且布隆过滤器的逻辑本身就不复杂,应该还是比较容易理解的…
class BloomFilter{
// 二进制向量(数组)的位数,相当于能存储1000万条url左右,误报率为千万分之一
private static final int BIT_SIZE = 2 << 28 ;
// 二进制数组(2^28 byte)
private BitSet bits = new BitSet(BIT_SIZE);
// 用于生成信息指纹的8个随机数,最好选取质数(使同一算法产生8个不同hash函数)
private static final int[] seeds = new int[]{3, 5, 7, 11, 13, 31, 37, 61};
// 用于存储具体的8个哈希对象(每个里面包含了不同结果的hash函数)
private Hash[] func = new Hash[seeds.length];
public BloomFilter(){
// 构造BloomFilter时生成这8个随机哈希对象
for(int i = 0; i < seeds.length; i++){
func[i] = new Hash(BIT_SIZE, seeds[i]);
}
}
/**
* 操作一:向过滤器中添加字符串
*/
public void addValue(String value)
{
if(value != null){
// 将字符串value哈希为8个或多个整数
for(Hash f : func)
//然后在这些整数的bit上变为1
bits.set(f.hash(value), true);
}
}
/**
* 操作二:判断字符串是否包含在布隆过滤器中
*/
public boolean contains(String value)
{
if(value == null)
return false;
boolean ret = true;
// 将要比较的字符串重新以上述方法计算hash值,再与布隆过滤器比对
for(Hash f : func)
// 注:这里 && ret 很关键,若有false了则能保证结果一定是false
ret = ret && bits.get(f.hash(value));
return ret;
}
/**
* 随机哈希值对象(静态内部类)
*/
public static class Hash{
private int size; // 二进制向量数组大小
private int seed; // 随机数种子
public Hash(int cap, int seed){
this.size = cap;
this.seed = seed;
}
/**
* 计算哈希值(也可以选用别的恰当的哈希函数)
*/
public int hash(String value){
int result = 0;
int len = value.length();
// 具体Hash算法:加权求和!!!
for(int i = 0; i < len; i++){
result = seed * result + value.charAt(i);
}
// 注:取模,得到具体二进制数组下标(result%(size-1))
return (size - 1) & result;
}
}
}
public class Test {
public static void main(String[] args){
BloomFilter b = new BloomFilter();
b.addValue("www.baidu.com");
b.addValue("www.sohu.com");
System.out.println(b.contains("www.baidu.com"));
System.out.println(b.contains("www.sina.com"));
}
}
4.Guava自带
除了自己实现,还可以直接使用guava包自带的布隆过滤器。
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>22.0</version>
</dependency>
下面是+redis的一个示例bloom filter java 【数据结构】布隆过滤器:BloomFilter原理及Java实现,目的是防止缓存穿透:
import com.google.common.hash.BloomFilter;
// 初始化布隆过滤器
// 1000:期望存入的数据个数,0.001:期望的误差率
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.forName("utf‐8")), 1000, 0.001);
//把所有数据存入布隆过滤器
void init(){
for (String key: keys) {
bloomFilter.put(key);
}
}
String get(String key) { 1
// 从布隆过滤器这一级缓存判断下key是否存在
Boolean exist = bloomFilter.mightContain(key);
if(!exist){
return "";
}
// 从缓存中获取数据
String cacheValue = cache.get(key);
// 缓存为空
if (StringUtils.isBlank(cacheValue)) {
// 从存储中获取
String storageValue = storage.get(key);
cache.set(key, storageValue);
// 如果存储数据为空, 需要设置一个过期时间(300秒)
if (storageValue == null) {
cache.expire(key, 60 * 5);
}
return storageValue;
} else {
// 缓存非空
return cacheValue;
}
}
1. 本站所有资源来源于用户上传和网络,如有侵权请联系站长!
2. 分享目的仅供大家学习和交流,您必须在下载后24小时内删除!
3. 不得使用于非法商业用途,不得违反国家法律。否则后果自负!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系站长处理!
6. 本站不售卖代码,资源标价只是站长收集整理的辛苦费!如果您喜欢该程序,请支持正版软件,购买注册,得到更好的正版服务。
7. 站长QQ号码 2205675299
资源库 - 资源分享下载网 » bloom filter java 【数据结构】布隆过滤器:BloomFilter原理及Java实现

常见问题FAQ
- 关于资源售价和售后服务的说明?
- 代码有没有售后服务和技术支持?
- 有没有搭建服务?
- 链接地址失效了怎么办?
- 关于解压密码







